Meta: This Article Is Also Posted on Medium.

“Good judgment comes from experience. Experience comes from bad judgment.”
Attributed to Nasrudin
Software Engineering has always stressed the importance of ensuring the product meets the specification.
In this essay, I turn that around, and suggest that we ensure that the specification meets the product.
This essay is basically a specialization of Forensic Design Documentation.
Quick Warning
The technique that I will explain here won’t necessarily scale that well to large, hybrid projects; especially those that may cross corporate or enterprise boundaries. It may also be unfriendly to organizations with a high degree of structure.
The “Draw Spunky” Test
From Day One, software developers are told how important it is to meet specification.
The typical academic exercise (and often, pre-employment) test, is to present the student/applicant with a short, well-specified word problem, (which may be accompanied by a pre-written piece of code), and ask them to improve/write code to meet specification.
Often, the exercise includes testing for proof that specification has been met. The student/applicant may be required to write these tests.
In every case, the test cannot be “passed” if the end result doesn’t meet the specification.
For example, let’s look at a simple list sort. The specification might say that the resulting list needs to be sorted, so that all “left” items point to lower values, and all “right” items point to higher values.
Going into the list at any point will result in being able to go in one direction for lower values, and the other direction for higher values. Endpoints are NIL (empty pointers), and complexity is worst-case O(n^n). The end result will be a linear, bidirectional, linked list, in order, from least, to most.
That’s a very clear specification. Meeting it is fairly straightforward.
Here’s A Curveball
That said, if I write code that makes it faster, I might actually violate specification; or, even worse, meet specification, and break the product.
An example of why this might be, is if the code is part of a larger system, where timed parallel processes are occurring, the code is being executed by a distributed system, or the technique used to accelerate the process could use system resources in a manner inconsistent with the use case (An example might be a mobile app, or embedded operating system, where high-performance code could drain the battery, break cache, or tie up scarce execution units in the processor).
Quick aside: I once worked on a driver, where the UART (the serial controller) was programmed using address bus locations (the lower 8 bits of the AB were mapped to control inputs). Just accessing an address was enough to change the state of the controller. In that case, using a separate “accumulator,” then executing a memory move after you were done, was the proper way to go, even if it looked messier.
Also, the specification dictates the storage format, which is a linked list. A hashed or indexed table might be a better structure for the application, where the sort metadata is in the hashes, or a separate index.
“So what?” you may snort. “Any engineer worth their salt wouldn’t make that mistake. If a hashed data storage is the best way to store the data, then of course they would specify it. If they were given a bad specification, then they would optimize the code to exceed the spec.”
Um…not really. Large project specifications are often aggregate efforts, with each section being designed by a different team.
Maybe the high-level software team deliberately specified a “naive” structure, like a linked list, or binary tree, expecting it to be optimized by “someone else,” not thinking that “someone else” might be one of those development shops that insists on Following. The. Specification. Exactly.
The other side of that coin, is that the author of the specification may assume that the specification will be followed exactly; but it is “improved” by the developer[s] creating the code to meet the specification. Remember what I said about mobile apps? True optimization is a black art. There are dozens of variables, coefficients and ramifications that aren’t at all obvious.
Since the specification might be a team effort, it’s entirely possible that we could have BOTH mindsets reflected in the specification, with no clear way to understand which section should be optimized, and which should be followed exactly.
One way to resolve this, would be to make sure that each specification section is annotated with guidance on implementation, but that’s not a particularly efficient (or, in some cases, realistic) approach.
Just to note: Sometimes “breaking the product” is exactly what we need. If, for example, parallel processes relied on timing, it may be a bad thing, and some hidden technical debt; so exposing this issue early would be a net gain.
Keeping Things Vague
The way that I like to work, is that the project plan is really used as the initial design specification, with a set of heuristics for each component of the project, as opposed to exact language.
Instead of a specific, unambiguous design for project tasks, the spec might be a list of resource constraints, and, possibly, exact specifications of API “choke points.”
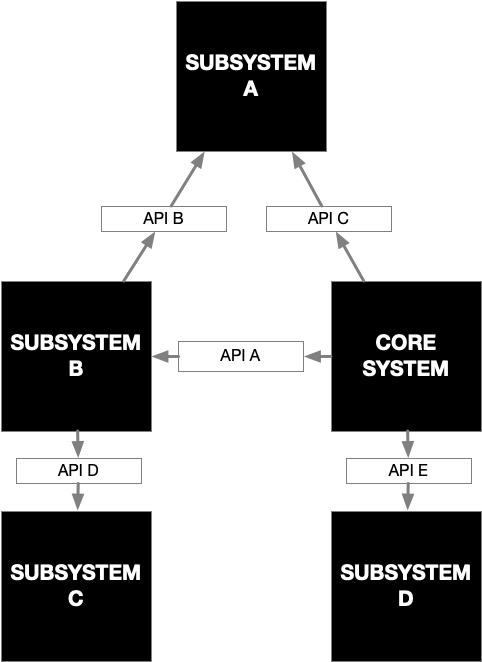
In the above diagram, we can leave the majority of the system as “black boxes,” and concentrate our exact requirements on the APIs that connect them. The black boxes may have “annotations,” explaining the constraints for the system (like resource usage requirements).
In fact, even the API specs could be somewhat “fuzzy,” with heuristics that describe ranges of behavior and values; giving implementors some leeway.
The whole idea is to reduce the “rigidity” of the specification process as much as possible, and allow it to proceed in a “just in time” fashion.
Fill In the Spec As We Proceed
My preference is to “flesh out” the specification as I proceed.
Better yet, I prefer to keep the spec as unwritten as possible. Every line we write down adds a bit of mortar to the concrete galoshes.
As the project proceeds, we review the system periodically, and make adjustments to whatever document exists. The best process, is if there is no document to adjust.
Don’t Skimp On the Tests
Testing is critical. When the spec is vague, I find that I need to make sure that integration testing (not just unit tests) is done.
This is a big reason that I prefer test harnesses over unit test suites (We can have both, but I like to start with test harnesses). Test harnesses test the code in a production-like environment, very quickly.
Document the Living Bejeezus Out of the Code
If the design spec is deprecated or eliminated, then maintainers need a source of “ground truth” to quickly familiarize themselves with the codebase and context.
My preference is to use utilities like Doxygen or Jazzy to “self-document” the codebase. This requires a VERY disciplined coding regimen, and I need to regularly review the documents for relevance and accuracy.
Since the documentation is actually embedded in the code, we have a natural version management system, at a very fine-grained level, of our technical documentation.
I will usually produce an insanely detailed README file, so that the GitHub repo has immediate relevancy, and I like to use the GitHub Pages facility to reference this auto-generated documentation.
If done correctly, I can get an enormous amount of highly relevant documentation that is matched exactly to the source code it documents. MUCH better than a separately-written and maintained document.
But That Won’t Work Everywhere
The model I espouse here would be considered nothing short of heresy by dedicated Waterfalliérs. It works great for the relatively small projects that I do, but would be difficult (Though I suspect, not impossible) to scale up.

I have spent most of my career in large organizations, with distributed, multi-disciplinary teams that need to coordinate some truly massive parallel projects (for example, releasing hardware and software in a coordinated fashion).
This is a fairly fraught process, and my experience is that it was ALWAYS handled in a fairly classic “Waterfall” model.
The Waterfall Model has many issues, and, to be honest, one of my dearest wishes is to never have to deal with that process again (probably an unreasonable goal).
Since branching out on my own, I have been prototyping what I call “ultra-agile” development methods.
This is one.